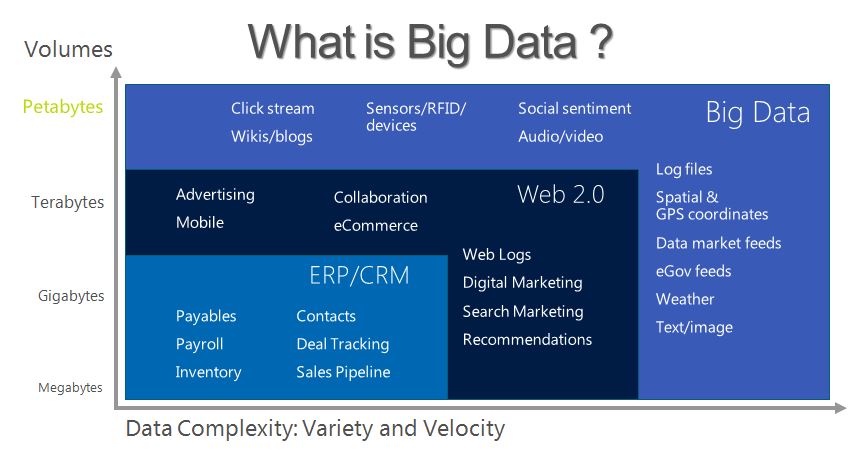
Il me paraît nécessaire de parler des Datas (données) dans le cadre de mon blog dédié au Marketing digital. En effet, l’évolution de la technologie permet de multiplier la collecte de données dans des proportions encore inimaginables quelques années en arrière. On constate ci-dessous que l’on peut structurer les données en trois groupes : données financières, données liées aux ventes et données « sociales ».

Le 3 juin 2015, j’ai eu la chance de participer à une conférence organisée par Microsoft à Genève et appelée « The life in a data driven world : Internet of Things, Big Data and Analytics for Experts ». On relevait les phénomènes suivants:
- Augmentation des volumes de données (50x croissance 2010-2020)
- Real-Time Data (340 mio tweets envoyés chaque jour, 204 mio eMails envoyés chaque minute)
- Nouveaux types de données (2.4 mio contenu facebook chaque minute, 1.3 mio de personnes sur Skype chaque heure).

On parle de Big Data puisqu’on assiste à une augmentation à un niveau très élevé vers trois fronts distincts: les 3 V de Volume, Variété et Vitesse!
«In God I trust, but all others bring data.»
(W. Edwards Deming, statisticien américain, 1900-1993)
Avec l’avènement de l’IoT (voir mon article The Internet of Things), on multiplie évidemment les occasions de collecter des données, via des capteurs, détecteurs, etc. Encore faut-il savoir quoi faire de ces données et comme les organiser et les traiter…
Un nouveau métier émerge donc de ce Big Data world, le Data Scientist, un professionnel de la modélisation des données, un métier à l’intersection entre l’IT, le Marketing et la Statistique. Je vous invite à lire cet article intéressant du Journal du Net qui explique bien les contours de ce job.
Qui dit Big Data dit aussi serveurs avec capacités quasi illimitées. De véritables Data Centers ont été construits autour du globe par les géants que sont Microsoft, Google, Apple, Facebook et consorts. En voici les éléments clés.

Conclusion : ce mouvement n’est pas prêt de s’arrêter, d’autant plus que les machines apprennent maintenant par elles-mêmes, voyez le Machine Learning (ML) ! C’est un apprentissage automatique. Le Machine Learning transforme les données en logiciel. Les Data Scientists créent le logiciel qui est formé à partir d’énormes volumes de données. Le logiciel peut envisager beaucoup plus de variables qu’un être humain pourrait le faire pour la même décision. A une époque où la quantité de données double tous les 18 mois environ, le Machine Learning peut utiliser toutes ces données pour résoudre les problèmes du business.
C’était un aperçu – non exhaustif – sur le sujet. Merci de votre attention – et peut-être du « partage »… puisqu’on vit dans un monde de Partage: des données, des expériences et des connaissances!
A bientôt!

Pour un article non exhaustif, il nous mets bien en appétit pour la suite. 😉
Il ne faut pas oublier que le ML comme tu le dis apprend par lui même, mais pour cela il faut lui apprendre. Cela veut dire prendre de son temps pour lui apporter une forme d’éducation… Nicolas Nova a récemment donné une conférence où il a dit qu’on y verra peut-être de nouveaux « business models » se créer autour de cette nouvelle forme d’apprentissage. Sa reste un sujet vaste, mais très intéressant donc merci pour cet article. 🙂
J’aimeJ’aime
Article intéressant qui a suscité deux questions: pertinence et saturation au niveau des 3V? Il y a tellement d’information. Si les systèmes les sauvegardent toutes, comment retrouver ce qui est juste, utile de ce qui est hoax et/ou futile? Existe-t-il un projet d’autodestruction des données par sujet ou par période temps? Ces points ont-ils evt été soulevés lors de la conférence Microsoft à Genève? Cheers xx
J’aimeJ’aime